
Introduction:
Hashing in Java play a pivotal role in optimizing data retrieval and storage in Java. In this comprehensive guide, we will explore the intricacies of hashing, including key concepts, implementation methods, and real-world applications.
Table of Hashing in Java
What is Hashing in Java
Hashing in Java is a fundamental technique that facilitates the storage of data in key-value pairs. It involves transforming the original key using a hash function, allowing the use of these modified keys as indices in an array. The associated data is then stored at the corresponding index location in a hash table for each key, creating an efficient and organized data structure.
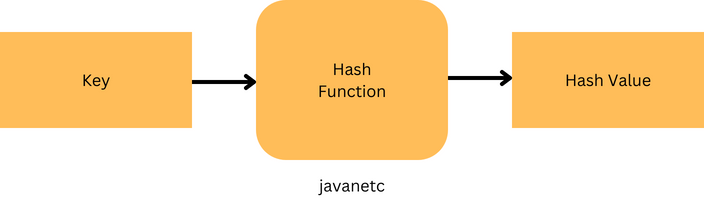
Hash Function
In the implementation of hashing in Java, a critical component is the hash function. This function plays a pivotal role as it transforms input keys into a consistent, fixed-size value known as the hash value. The result generated by the hash function is commonly referred to as the hash value, hash code, or simply hashes. This process is central to the efficient mapping of keys to indices, facilitating organized storage and retrieval of data in hash tables.
Hash Table
A hash table serves as an array containing pointers to data associated with hashed keys. By employing hash values as location indices, the hash table efficiently organizes and preserves the linked data within the array.
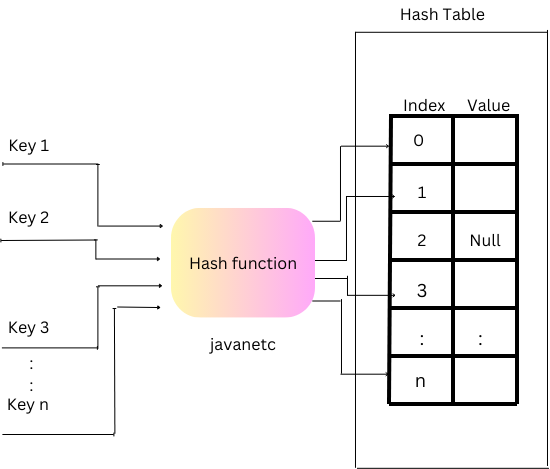
In essence, the provided keys undergo a transformation into hash values through a hash function. These hash values, in turn, function as indices within the hash table, facilitating the storage of corresponding data.
The process of hashing in Java encapsulates the comprehensive procedure of storing data in a hash table, adopting a key-value pair format. The key is determined through the computation of a hash function, thereby orchestrating the systematic storage and retrieval of data.
Understanding Hashing in Java Concepts:
Hashing in Java involves mapping data to a fixed-size value, allowing for efficient indexing and retrieval. The key component is the hash function, which generates a hash code from the input data. In Java, the hashCode() method is commonly used for this purpose.
@Override
public int hashCode() {
return Objects.hash(key, value);
}
Here, the Objects.hash() utility combines the hash codes of ‘key’ and ‘value’ to create a unique hash code for each object.
Collision Resolution Strategies
Despite efforts to create unique hash codes, collisions, where different keys produce the same hash code, can occur. Two widely used collision resolution strategies in Java are:
Chaining
Chaining involves creating linked lists at each hash code index to accommodate multiple values. In the event of a collision, new values are added to the existing linked list.
Open Addressing
Open addressing resolves collisions by finding the next available slot in the array. Techniques like linear probing, quadratic probing, or double hashing are commonly employed.
Implementation Methods Hashing in Java
1. HashTable-based Method (Synchronized Implementation)
import java.util.Hashtable;
public class HashTableDemo {
public static void main(String args[]) {
Hashtable<Integer, String> hm = new Hashtable<>();
hm.put(3, "You are visiting");
hm.put(5, "Hello");
hm.put(1, "website");
hm.put(2, "Javatpoint");
System.out.println(hm);
}
}
The Hashtable class provides a synchronized implementation, ensuring thread safety but potentially sacrificing performance.
2. HashMap-based Method (Non-Synchronized, Faster)
import java.util.HashMap;
public class HashMapDemo {
static void HashMapCreation(int arr[]) {
HashMap<Integer, Integer> hashmap = new HashMap<>();
for (int i = 0; i < arr.length; i++) {
Integer n = hashmap.get(arr[i]);
if (hashmap.get(arr[i]) == null) {
hashmap.put(arr[i], 1);
} else {
hashmap.put(arr[i], ++n);
}
}
System.out.println(hashmap);
}
public static void main(String[] args) {
int arr[] = {1, 6, 5, 10, 6, 6, 10};
HashMapCreation(arr);
}
}
HashMap offers a non-synchronized, faster alternative for hashing, suitable for scenarios where thread safety is not a critical concern.
3. LinkedHashMap-based Method (Maintains Element Order)
import java.util.LinkedHashMap;
public class LinkedHashMapDemo {
public static void main(String arg[]) {
LinkedHashMap<String, String> lhm = new LinkedHashMap<>();
lhm.put("One", "Robin");
lhm.put("Two", "Satyam");
lhm.put("Three", "Kanishk");
System.out.println(lhm);
}
}
LinkedHashMap maintains the order of elements, making it suitable for scenarios where the insertion order needs to be preserved.
4. ConcurrentHashMap-based Method (Synchronized, High Performance)
import java.util.concurrent.ConcurrentHashMap;
public class DemoForConcurrentHashMap {
public static void main(String[] args) {
ConcurrentHashMap<Integer, String> ch = new ConcurrentHashMap<>();
ch.put(201, "How");
ch.put(202, "are");
ch.put(203, "you");
System.out.println("ConcurrentHashMap: " + ch);
ch.putIfAbsent(202, "How");
System.out.println("\nConcurrentHashMap: " + ch);
ch.replace(201, "How", "Who");
System.out.println("\nConcurrentHashMap: " + ch);
ch.remove(203, "you");
System.out.println("\nConcurrentHashMap: " + ch);
}
}
ConcurrentHashMap combines synchronization with high performance, utilizing multiple locks for efficiency.
How does Hashing Work?
Hashing in Java operates through a concise two-step process:
- Firstly, a hash function transforms an input key into hash values.
- Subsequently, this hash value serves as an index within the hash table, where the corresponding data is stored.
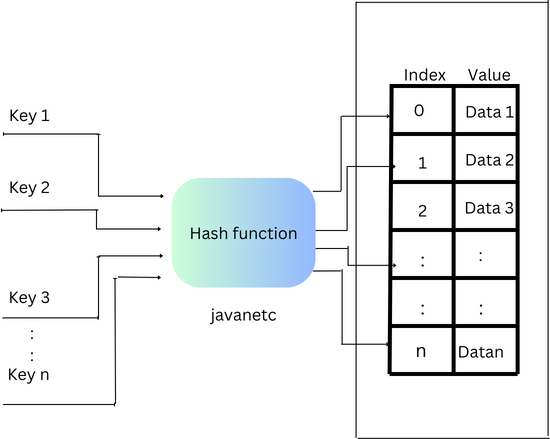
The mechanism of hashing involves storing elements in a hash table, allowing for swift data retrieval using the hashed key. To retrieve data, we calculate the hash value for a given key, utilizing it as an index to extract the associated data from the hash table.
| Token No. | Name |
| 16 | Virat |
| 1 | Alex |
| 40 | Ishika |
| 5 | Sonu |
| 3 | Mrinalini |
| 38 | John |
Illustrating the process with a scenario, imagine managing a list of people scheduled for vaccination, each identified by a unique token number. The objective is to create an efficient and space-conscious hash table for data storage and retrieval.
Initially, a naive solution might involve using an array of size 41, with each key (token number) serving as an index. However, this approach is inefficient, leading to wasted space as data is stored in only a fraction of the array’s locations.
Here’s where hashing comes into play. By employing a hash function, we can convert keys into more condensed hashed keys. This ensures that the characteristics of an effective hash function, as discussed earlier, are maintained.
In the vaccination scenario, this means narrowing down the search space. Instead of using an array of 41, we employ a hash function to generate hashed keys, optimizing the storage of data at specific indices. This approach significantly enhances efficiency, ensuring that the majority of the array space is utilized effectively for data storage and retrieval.
Choosing hash function
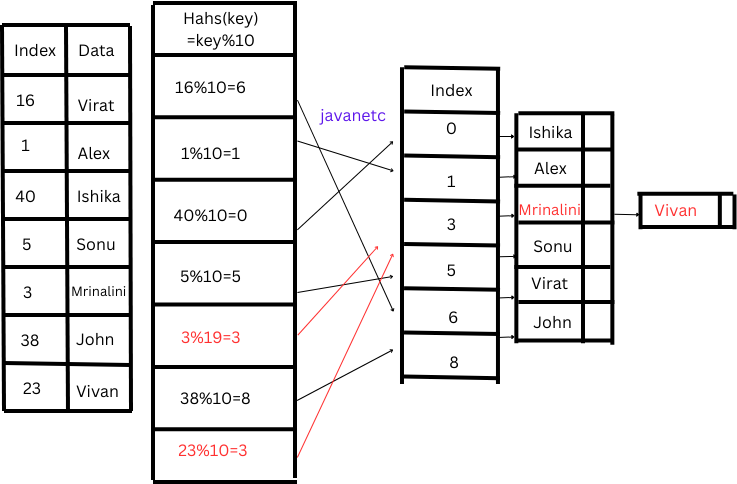
In the process of implementing a hash function, a critical step involves selecting an appropriate function that effectively transforms keys into hash values. A careful examination of the keys reveals that they can be easily converted to numbers ranging from 0 to 10 by using the hash function:
Hash(key)=keymod10
Applying this hash function, we can observe that Hash(16)=16mod 10=6Hash(16)=16mod10=6, indicating that the value corresponding to the key 16 (i.e., “Virat”) will be stored in the array at index 6. Similarly, other keys can be hashed in a similar manner to find suitable locations in the array.
To optimize the hash table, its size should be set to 10, as the hash function can generate hash values from 0 to 9.
| Token No. | Name | Hash(key) = keymod10 |
| 16 | Virat | 16 mod 10=6 |
| 1 | Alex | 1 mod 10=1 |
| 40 | Ishika | 40 mod 10=0 |
| 5 | Sonu | 5 mod 10=5 |
| 3 | Mrinalini | 3 mod 10=3 |
| 38 | John | 38 mod 10=8 |
So, our hash table will look like:
| Index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Value | Ishika | Alex | Mrinalini | Sonu | Virat | John |
Now, if we wish to retrieve the name of the person with token number 38, we can generate an index using the hash function:
index=hash(38)=38mod10=8
We can then obtain the value from the array; table[8]table[8] will return “John” as the name of that person.
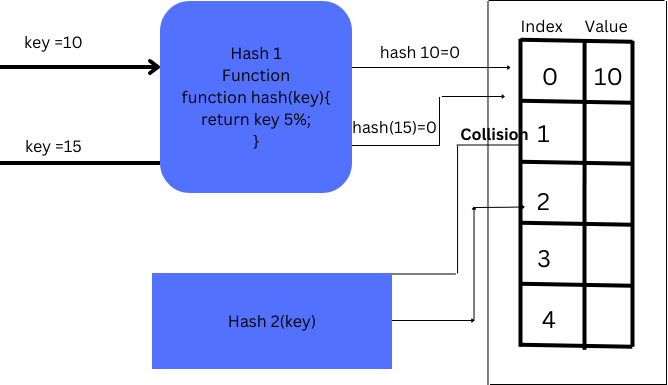
However, if we introduce another person’s data with token number 23, the same hash values would be generated for both 23 and 3. This scenario, known as collision, arises when two different keys produce the same hash value. Various techniques exist to address and resolve collisions effectively.
Chaining:
If collisions persist despite efforts to minimize them through the hash function, an alternative solution involves using an array of LinkedLists as a hash table. The essence of chaining lies in having each hash table slot direct to a linked list containing records that share the same hash value. This technique, known as chaining in Java, ensures efficient storage of data, providing a practical resolution for collision scenarios.
Double Hashing in java:
In double hashing, two hash functions are employed to address collisions, activating the second hash function when collisions occur.
Conclusion:
Mastering hashing in Java is essential for creating efficient and performant applications. Each implementation method has its strengths and use cases, allowing developers to choose the right tool for the job. Whether prioritizing thread safety, speed, or maintaining element order, Java’s diverse hashing methods cater to a spectrum of needs in the ever-evolving landscape of computer science.


{kind=link}