
Introduction
ScyllaDB, a relatively nascent yet rapidly gaining database, has become a beacon for major tech companies dealing with colossal datasets. The likes of Discord, Apple, Sharechat, Epic Games, and Comcast are steering their data management strategies towards ScyllaDB. This surge in adoption is exemplified by ScyllaDB’s astounding 200-fold rise in the DB-engines ranking in recent years. This article embarks on a detailed exploration of the reasons underpinning the growing popularity of ScyllaDB and the motivations behind the migration of data-intensive applications to this innovative database.
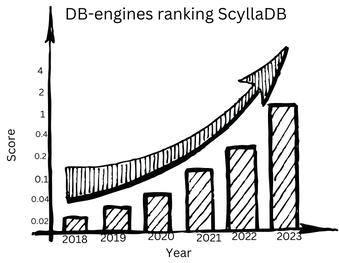
Table of Contents
Prerequisites:
Before delving into the intricacies of ScyllaDB, it’s imperative to revisit fundamental concepts such as the Java Virtual Machine (JVM) and garbage collection. Understanding how JVM abstracts complex problems like memory management provides a foundational backdrop for comprehending the unique challenges faced by databases dealing with massive data sets.
The article also touches on the significance of CPU cores, threads, and the challenges posed by resource contentions in multi-core server environments. This sets the stage for a nuanced exploration of distributed databases’ partitioning strategies, where data is segmented into smaller units known as “partitions” or “shards.”
JVM and Garbage Collection
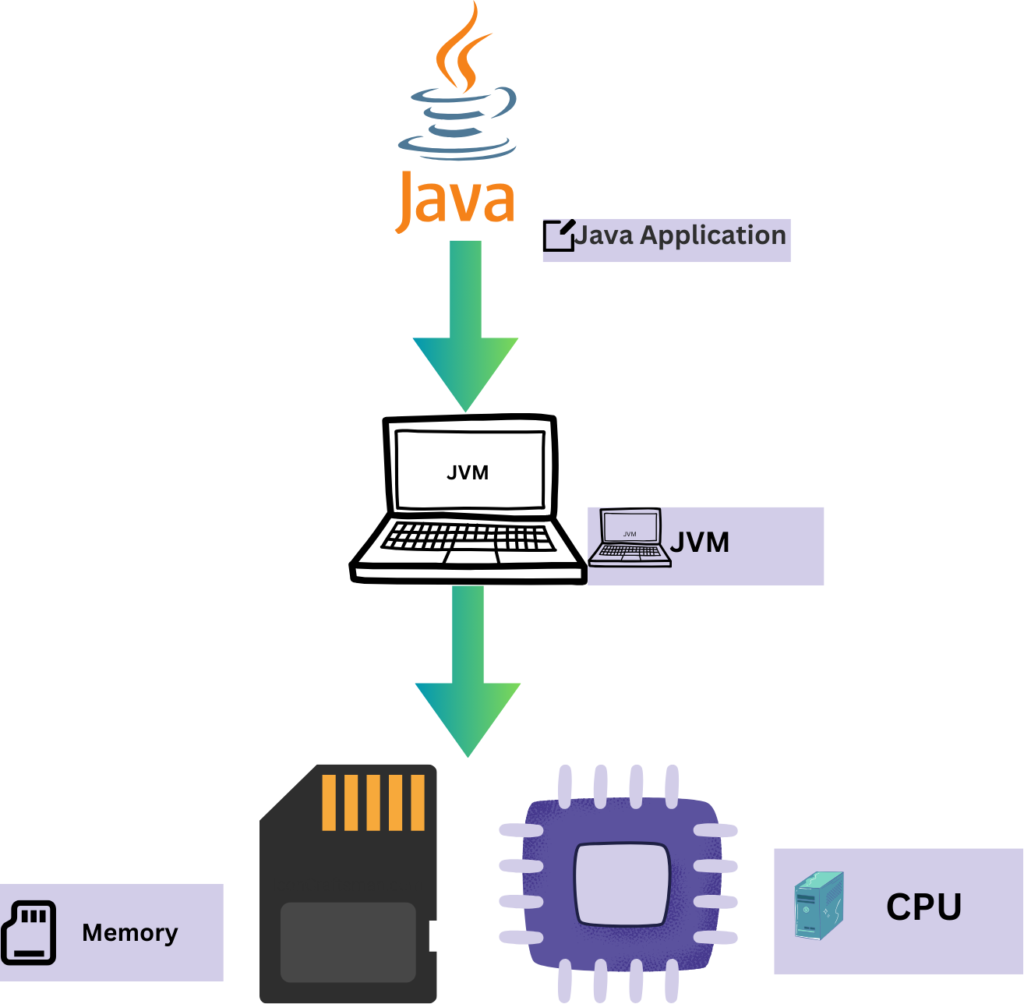
The Java Virtual Machine (JVM) serves as the backbone of Java’s cross-platform prowess, translating human-readable code into machine-executable instructions. JVM’s abstraction layer shields developers from low-level intricacies, enabling Java’s “write once, run anywhere” capability.
At the heart of JVM’s efficiency lies Garbage Collection, a memory management process crucial for optimal resource utilization. It identifies and disposes of unused variables, preventing memory leaks and ensuring application robustness.
However, the periodic nature of Garbage Collection introduces challenges, especially in data-intensive scenarios. In multi-core environments, contention among CPU cores during cleanup can lead to execution delays, impacting performance. In databases, where large datasets are manipulated, Garbage Collection-induced CPU spikes and IO bottlenecks can affect critical operations.
Efforts to optimize Garbage Collection algorithms and explore alternative languages signal ongoing advancements. While challenges persist, JVM’s role in Java’s adaptability remains pivotal, with continual innovations shaping the landscape of memory management in Java applications.
CPU cores, Threads, Resource Contentions
Let’s quickly review CPU cores, threads, and the concept of resource contention.
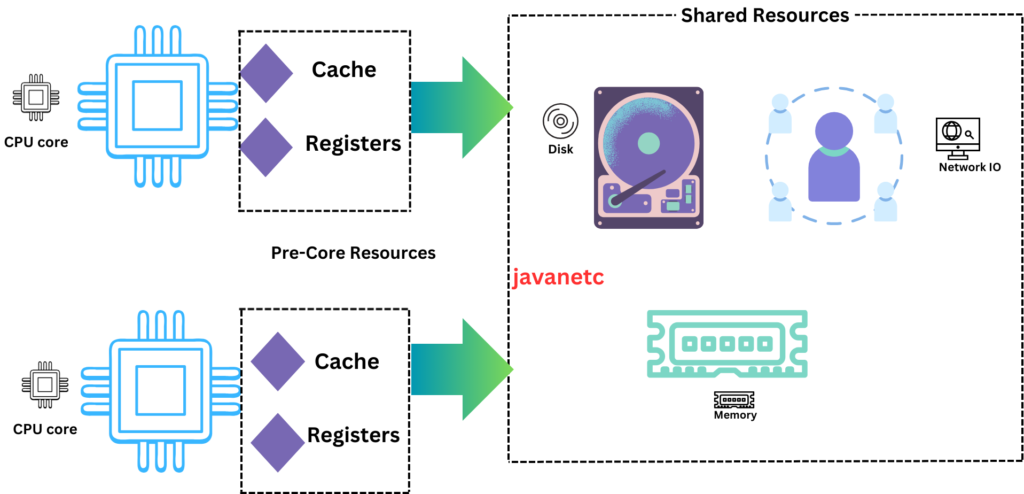
In the server landscape, most CPUs are equipped with multiple cores, each functioning as an independent processing unit capable of parallel execution. To illustrate, envision a team of software engineers, each dedicated to working on individual features.
To perform any task, the CPU must access various resources within the system, including caches, registers, RAM, disk, and the network. Each core, in addition to its thread of execution, is allocated a specific set of resources such as L1 and L2 caches and registers. However, resources like disk and RAM are shared among all cores.
In essence, this setup can be likened to the collaboration of engineers in a team, where each member has their workstation (core) and a specific set of tools (resources), but certain resources like meeting rooms (disk and RAM) are shared collectively. This shared access to resources, when not managed efficiently, can lead to contention issues, causing delays in task execution.
Cassandra and Its Challenges:
Let’s delve into Cassandra, a database that has left an indelible mark in the tech industry. With over 7.3k stars on GitHub and adoption by tech giants like Apple, Discord, Activision, Best Buy, and Netflix, Cassandra is a heavyweight in the database realm, tackling substantial data challenges.
So, what is Cassandra?
Cassandra stands as a formidable NoSQL database renowned for its prowess in handling vast datasets and functioning seamlessly as a distributed database. While many databases can operate in a distributed environment, Cassandra distinguishes itself by how effortlessly it integrates into such systems. There’s a common jest in the tech community that running Cassandra as a single-node system is more challenging than in a distributed setup. It’s as if using Cassandra in a single-node configuration is akin to driving a Lamborghini through city traffic – it feels like an underutilization of its inherent potential.

The allure of Cassandra lies in its distributed nature, intricately woven into its design. Running it as a distributed system aligns with its natural state, emphasizing its scalability and efficiency. This contrasts sharply with the notion of running it on a single node, which might be perceived as an opportunity lost, reminiscent of driving a high-performance car in stop-and-go city traffic.

However, as with any powerful tool, Cassandra comes with its set of challenges. While it excels in distributed environments, managing it as a single-node system poses its own complexities. The analogy here is reminiscent of even the most luxurious cars facing challenges in terms of fuel efficiency.
In essence, Cassandra’s popularity stems from its ability to navigate the complexities of large-scale data management effortlessly, especially in distributed scenarios, where its true potential shines.
The Birth of ScyllaDB:
The narrative then transitions to ScyllaDB’s inception, revealing that its genesis lies in the realization that Cassandra struggles to efficiently utilize OS resources. In response, the ScyllaDB team undertakes a monumental task—rewriting the Cassandra architecture from scratch in native code, specifically C++. This strategic move aims to create a database that retains Cassandra’s surface functionality while internally revolutionizing resource utilization for enhanced efficiency.
ScyllaDB and Cassandra: A Comparative Analysis:
The article meticulously compares ScyllaDB with its predecessor, Cassandra, shedding light on key differentiators that propel ScyllaDB into the limelight.
- Fully Compatible API: ScyllaDB’s API, designed with a laser focus on performance improvement, remains fully compatible with Cassandra. This seamless compatibility facilitates a smooth transition, requiring no alterations to existing application code. The migration process becomes a matter of redirecting endpoints while retaining the same libraries and CQL queries.
- Linear Scaling: One of ScyllaDB’s standout features is its achievement of linear scaling. Unlike traditional database clusters, where the addition of new nodes can burden existing ones, ScyllaDB’s independent node behavior ensures that scaling is almost linear. This is likened to a team of engineers working on tasks that can be accomplished independently, reducing inter-node dependencies.
- Java vs C++: A pivotal distinction emerges in the choice of programming languages. While Cassandra relies on Java, ScyllaDB is written in C++, providing lower-level access to the operating system. This distinction empowers ScyllaDB with more efficient memory management, freeing it from the periodic interruptions of garbage collection pauses.
- Priority IO Classes: ScyllaDB introduces the concept of IO classes to prioritize certain IO operations over others. By assigning priorities, ScyllaDB optimizes the order in which operations are processed. This prioritization ensures that critical or time-sensitive tasks receive precedence, resulting in improved system responsiveness and reduced latencies.
- Shard-per-core and shared-nothing architecture: The article elucidates how ScyllaDB addresses resource contention by adopting a shard-per-core architecture. Each shard runs on a dedicated core with its set of CPU, memory, disk, and network IO resources. This design minimizes dependencies and contention, allowing partitions to operate more independently.
Conclusion and Further Reading:
The exploration concludes by emphasizing ScyllaDB’s meteoric rise as an exceptionally high-performance database, lauded for its efficient resource utilization. It encourages readers to delve deeper into the realm of Dynamo-inspired databases, highlighting the shift towards data-intensive solutions prioritizing high-write, fault-tolerant architectures over traditional ACID compliance. The suggested reading path includes understanding the foundational concepts behind Dynamo, exploring Cassandra in detail, and immersing oneself in the evolving landscape of high-performance databases. ScyllaDB emerges as a pivotal player in this paradigm shift, beckoning database enthusiasts and practitioners alike to explore its capabilities and contributions to the evolving data-centric ecosystem.


{kind=link}